做数据分析的朋友都知道,获取干净规范的财务数据是最基础却也最耗时的环节。最近我在制作贵州茅台(600519)的PowerBI分析仪表盘时,深刻体会到了这个痛点——手动从新浪财经等网站逐一下载资产负债表、利润表等财报,不仅要忍受繁琐的页面跳转,抓取的表格格式也五花八门,光是数据清洗就花了大半天时间。
为了解决这个效率瓶颈,我用Python开发了一款《财务报表数据抓取工具》。这款桌面应用彻底改变了获取财报数据的体验,让原始数据采集变成了可批量操作的自动化流程,为后续的PowerBI建模扫清了障碍。
核心功能设计思路:
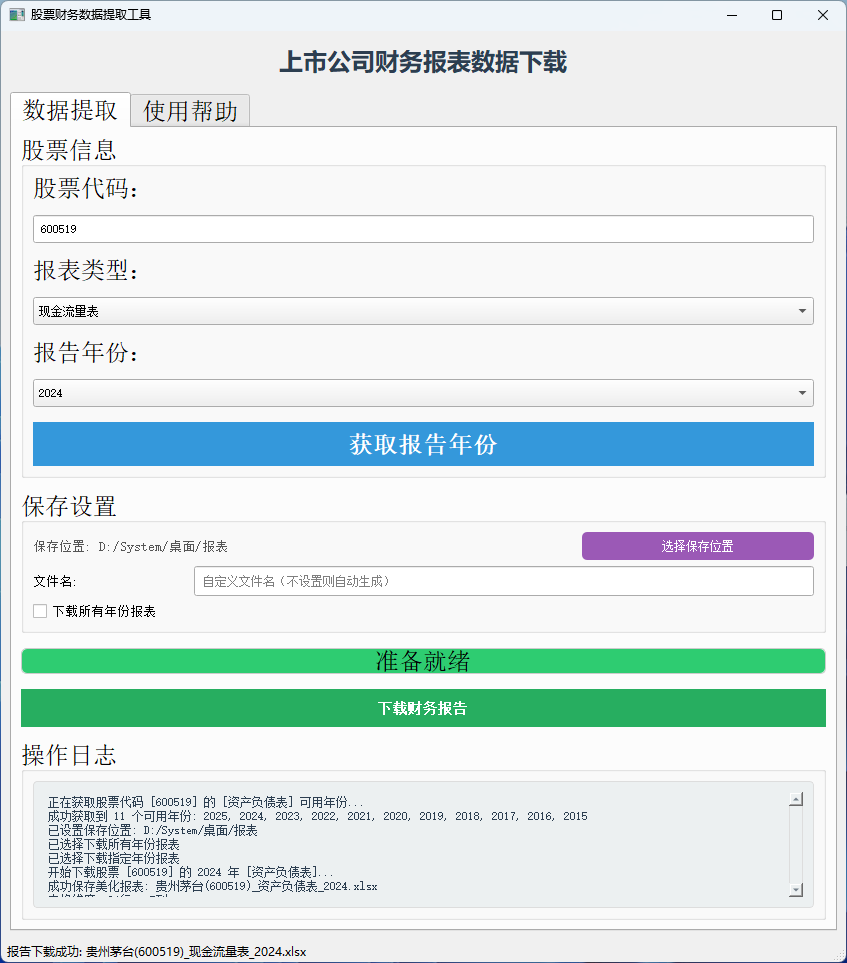
一键抓取三大核心报表 只需输入股票代码,工具就能自动识别并获取新浪财经上的资产负债表、利润表和现金流量表。针对A股特有的6位代码格式做了优化,支持从
600519(茅台)到300750(宁德时代)等各板块股票。历史数据批量下载机制 PowerBI的时间序列分析需要连续多年的财务数据。工具独创性地设计了"批量下载所有年份"功能,自动识别上市公司可用的全部历史年份,并同步下载每个年度的报表,构建完整时间维度的数据集。
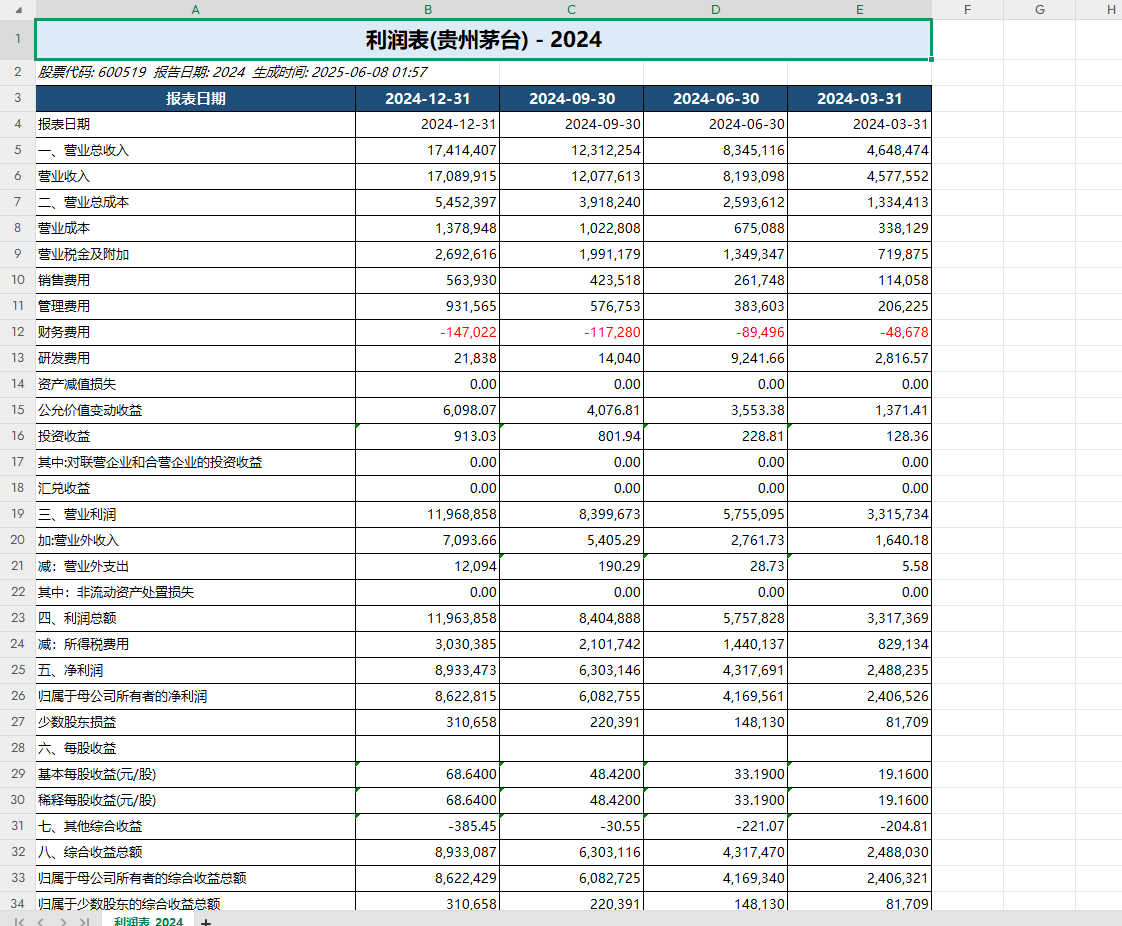
智能Excel格式美化 为解决原始表格格式混乱的问题,工具内置了专业级的Excel美化模块:
重要科目自动加粗+底色高亮(如流动资产、负债总额等关键行)
千分位分隔+负数红字标识,符合财务规范
自动冻结首行首列,保持标题可见性
添加数据来源和免责声明页脚
无缝对接分析生态 生成的Excel可直接导入PowerBI或Python分析环境:
# PowerBI导入示例
from powerbiclient import QuickVisualize, get_dataset_config
report = QuickVisualize(get_dataset_config(pd.read_excel('600519_利润表_2023.xlsx')))
report技术实现亮点:
多线程数据抓取架构 通过PyQt5的QThread类实现后台线程抓取,避免界面卡顿。当用户点击"下载2020-2023年数据"时,实际在后台同步进行着:
class DataFetcher(QThread):
def fetch_all_years(self):
# 获取年份列表
years = self.parse_years_from_html()
for year in years:
self.progress.emit(f"下载{year}年数据...")
data = self.fetch_single_report(year)
self.save_excel(data)自适应表格解析算法 针对不同报表类型设计独立的HTML解析规则:
if report_type == "资产负债表":
table = soup.find('table', {'id': 'BalanceSheetNewTable0'})
elif report_type == "利润表":
table = soup.find('table', {'id': 'ProfitStatementNewTable0'})开箱即用的桌面体验 采用PyQt5构建的图形界面包含:
智能引导工作流(股票代码→报表类型→年份→保存)
实时日志追踪(显示每一步操作结果)
进度条动态反馈
响应式布局
使用效果对比:
在最近的白酒行业分析项目中,这个工具让我节省了90%的数据准备时间。过去需要整天手动整理的10家上市公司5年财报数据,现在午休时间就能自动抓取完成,数据质量却更加稳定可靠。
展望与启发:
这套工具不仅是数据采集的技术方案,更提供了可复用的开发范式:
Python+PyQt5开发专业桌面应用的路径
爬虫技术与GUI设计的有机结合
财务数据ETL(Extract, Transform, Load)的全流程实现
未来计划将其扩展为支持多数据源的版本,集成到PowerBI的数据流体系,最终目标是实现"输入股票代码→获取分析仪表盘"的一站式解决方案。